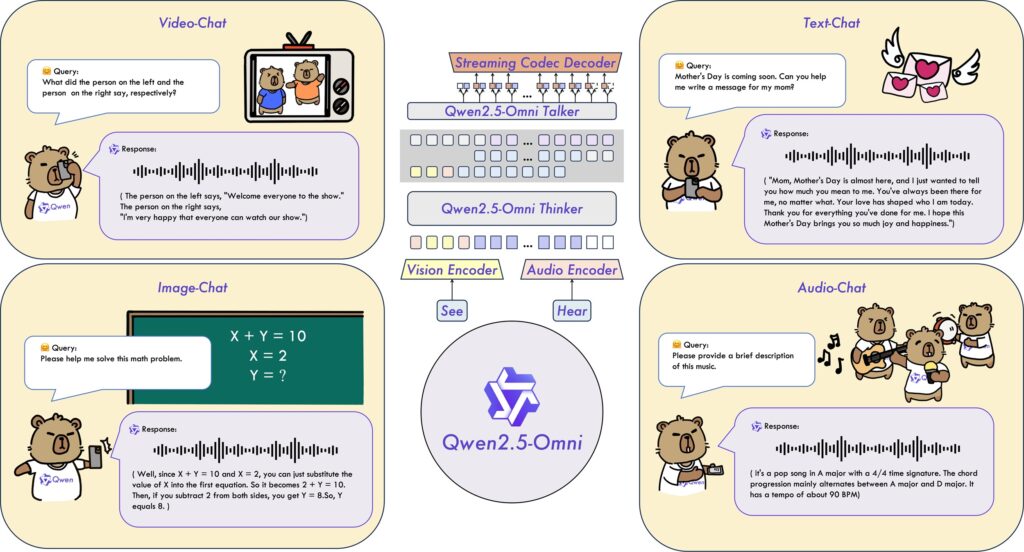
อาลีบาบา คลาวด์ เปิดตัว Qwen2.5-Omni-7B โมเดลมัลติโหมด (multimodal model) ครบวงจรเป็นส่วนหนึ่งใน Qwen series โมเดลนี้ออกแบบมาโดยเน้นความสามารถในการเข้าใจประเภทของข้อมูลได้หลายรูปแบบและครอบคลุม สามารถประมวลผลอินพุตหลากหลาย รวมถึงข้อความ รูปภาพ เสียง และ วิดีโอ สามารถสร้างการตอบสนองด้วยข้อความและคำพูดที่เป็นธรรมชาติได้แบบเรียลไทม์ นับเป็นการตั้งมาตรฐานใหม่ให้กับ multimodal AI ที่สามารถปรับใช้กับอุปกรณ์ปลายทาง (edge devices) เช่น โทรศัพท์มือถือ และแล็ปท็อปได้อย่างเหมาะสม
โมเดลนี้มอบประสิทธิภาพที่ไม่มีแผ่ว และมอบความสามารถแบบมัลติโหมดที่ทรงพลัง แม้ว่าจะมีพารามิเตอร์ขนาดกะทัดรัดเพียง 7B เท่านั้น จึงเป็นการผสมผสานรากฐานที่สมบูรณ์แบบเข้ากับการพัฒนา AI agents ที่คล่องตัวและคุ้มค่า มอบคุณประโยชน์ที่จับต้องได้ โดยเฉพาะกับแอปพลิเคชันเสียงอัจฉริยะต่าง ๆ เช่น โมเดลนี้ช่วยเปลี่ยนให้คุณภาพชีวิตดีขึ้น โดยการช่วยนำทางผู้มีความบกพร่องทางการมองเห็น ผ่านคำอธิบายเสียงเกี่ยวกับสภาพแวดล้อมแบบเรียลไทม์ หรือ ให้คำแนะนำในการทำอาหารทีละขั้นตอนด้วยการวิเคราะห์ส่วนผสมจากวิดีโอ หรือ ขับเคลื่อนให้บริการลูกค้าอัจริยะสามารถใช้บทสนทนาที่เข้าใจความต้องการที่แท้จริงของลูกค้าได้
ปัจจุบันโมเดลนี้เปิดเป็นโอเพ่นซอร์สบน Hugging Face และ GitHub และสามารถเข้าใช้ผ่าน Qwen Chat และ ModelScope ซึ่งเป็นชุมชนโอเพ่นซอร์สของอาลีบาบา คลาวด์ ทั้งนี้ในหลายปีที่ผ่านมา อาลีบาบา คลาวด์ ได้เปิดให้โมเดล generative AI มากกว่า 200 โมเดลเป็นโอเพ่นซอร์ส
นวัตกรรมด้านสถาปัตยกรรม ขับเคลื่อนให้โมเดลมีประสิทธิภาพสูง
Qwen2.5-Omni-7B มอบประสิทธิภาพโดดเด่นให้กับโหมดทุกประเภท ได้ทัดเทียมกับโมเดลเฉพาะแบบโหมดเดียวต่าง ๆ (single-modality models) ที่มีขนาดใกล้เคียงกัน โดยเฉพาะอย่างยิ่ง โมเดลนี้ได้ตั้งมาตรฐานใหม่ด้านการปฏิสัมพันธ์ด้วยเสียงแบบเรียลไทม์ การสร้างเสียงพูดที่เป็นธรรมชาติและชัดเจน และการทำตามคำสั่งเสียงอย่างครบวงจรจากต้นจนจบ
ประสิทธิภาพและสมรรถนะที่สูงของโมเดลนี้มาจากการใช้สถาปัตยกรรมล้ำสมัย ซึ่งรวมถึง Thinker-Talker Architecture ที่แยกการสร้างข้อความ (ด้วย Thinker) และการสังเคราะห์เสียง (ด้วย Talker) ออกจากกัน เพื่อลดสัญญาณรบกวนจากโหมดต่าง ๆ ให้เหลือน้อยที่สุดเพื่อให้ได้เอาต์พุตคุณภาพสูง, TMRoPE (Time-aligned Multimodal RoPE) ซึ่งเป็นเทคนิคการฝังตำแหน่งเพื่อให้ซิงโครไนซ์อินพุตวิดีโอด้วยเสียงเพื่อสร้างเนื้อหาที่สอดคล้องกันได้ดีขึ้น, และ Block-wise Streaming Processing ที่ช่วยให้สามารถตอบสนองเสียงด้วยความรวดเร็วมีความหน่วงต่ำ ส่งผลให้การโต้ตอบด้วยเสียงเป็นไปอย่างราบรื่น
Qwen2.5-Omni-7B ได้รับการเทรนล่วงหน้าด้วยชุดข้อมูลที่หลากหลายและกว้างขวาง ซึ่งรวมถึง การเปลี่ยนภาพเป็นข้อความ, วิดีโอเป็นข้อความ, วิดีโอเป็นเสียง, ตัวอักษรเป็นข้อมูล เพื่อให้มั่นใจได้ว่าโมเดลจะสามารถทำงานได้ทุกแบบด้วยประสิทธิภาพสูง
สถาปัตยกรรมที่ล้ำสมัยและการเทรนล่วงหน้าด้วยชุดข้อมูลคุณภาพสูง ทำให้โมเดลนี้มีความเป็นเลิศด้านการทำตามคำสั่งเสียง และมีประสิทธิภาพเทียบเท่ากับการป้อนเป็นตัวอักษรข้อความล้วน ๆ สำหรับงานที่เกี่ยวข้องกับมัลติโหมด เช่น โมเดลที่ได้รับการประเมินผ่าน OmniBench ซึ่งเป็นเกณฑ์มาตรฐานที่ประเมินความสามารถของโมเดลต่าง ๆ ด้านการจดจำ การตีความ และการให้เหตุผล จากอินพุตที่เป็นภาพ เสียงและข้อความ จึงกล่าวได้ว่า Qwen2.5-Omni มีสมรรถนะล้ำสมัยที่สุดในปัจจุบัน
Qwen2.5-Omni-7B ยังแสดงให้เห็นว่ามีสมรรถนะในการทำความเข้าใจและการสร้างคำพูดที่ดีเยี่ยม และมีความสามารถในการสร้างคำพูดผ่านการเรียนรู้ลงลึกในเชิงบริบท (in-context learning: ICL) นอกจากนี้ หลังจากเสริมประสิทธิภาพด้วยการเรียนรู้แบบเสริมกำลัง (reinforcement learning: RL) หรือการเรียนรู้จากปฏิสัมพันธ์แบบลองผิดลองถูกที่เกิดขึ้นระหว่างทางของการเรียนรู้แล้ว Qwen2.5-Omni-7B ได้แสดงให้เห็นว่ามีความเสถียรในการสร้างคำพูดเพิ่มขึ้นอย่างมาก ลดความคลาดเคลื่อนในการให้ความสนใจ, ลดข้อผิดพลาดในการออกเสียง และลดการสะดุดหยุดลงระหว่างการตอบสนองด้วยคำพูดได้อย่างเห็นได้ชัด
อาลีบาบา คลาวด์ เปิดตัว Qwen2.5 เมื่อเดือนกันยายนปี 2567 และปล่อย Qwen2.5-Max สู่ตลาดในเดือนมกราคมปี 2568 และได้รับการจัดให้อยู่ในอันดับที่ 7 บน Chatbot Arena ซึ่งเทียบชั้นได้กับ LLM ชั้นนำทั้งหลายที่มีกรรมสิทธิ์ และยังแสดงให้เห็นถึงความสามารถที่โดดเด่นด้านต่าง ๆ อาลีบาบา คลาวด์ยังได้เปิดโอเพ่นซอร์ส Qwen2.5-VL และ Qwen2.5-1M ตอบโจทย์การทำความเข้าใจภาพที่มีประสิทธิภาพมากขึ้น และจัดการกับอินพุตบริบทที่ยาว ๆ ได้ดีขึ้น




